Doctor Honoris Causa: Eduardo Fradkin
- 16-07-2026 15:30 |
- Aula 1401. Cero + Infinito
Un estudio cuantitativo realizado por investigadores Pablo Balenzuela y Claudio Dorso junto a Sebastián Pinto y Federico Albanese compara similitudes y distancias entre la agenda de cinco diarios nacionales con las búsquedas que realizaron los usuarios de Google y Twitter sobre los mismos temas en igual período de tiempo. El objetivo del trabajo es conocer el ecosistema del flujo de información en sistemas sociales complejos y el interés de los públicos según las búsquedas que realizan.
Los estudios de "Agenda Setting" nacieron en los años setenta y hoy se consideran clásicos en el estudio de comunicación de masas. Las ciencias sociales se han preguntado por la influencia que tienen los medios masivos en la formación de opinión pública, los consumos y las elecciones políticas desde entonces. Hoy, la generación de datos a toda escala permite ensayar otros interrogantes y tender puentes metodológicos entre disciplinas en búsqueda de nuevos tiposdeanálisis.
En este sentido, los investigadores han retomado conceptos tradicionales de las teorías de la comunicación para definir variables de análisis y poder generar mediciones. Así, por un lado, definen la agenda de medios en base a la distribución de palabras y sus correlaciones en cierto corpus de noticias y, por otro lado, a la agenda pública como el análisis de las búsquedas que los usuarios realizaron en internet sobre los mismos temas. La medición de la diversidad de agenda se realizó en función del tiempo usando la entropía de Shannon; y las diferencias entre las agendas en términos de la distancia de Jensen-Shannon.
Diversidad de agenda
El corpus de análisis elegido por el grupo se compone de noticias publicadas entre el 31 de julio y el 5 de noviembre de 2017. Los artículos provienen de la sección política del portal de noticias Infobae y de las ediciones en línea de Clarín, La Nación y Página/12. El conjunto analizado está compuesto por 11815 artículos en total: 2908 de Clarín, 3565 de La Nación, 3324 de Página/12 y 2018 de Infobae.
“Primero identificamos el espacio de tópicos, es decir, definimos los ejes temáticos principales de los que hablan las noticias y lo hacemos utilizando una técnica de clustering -de agrupamiento-. En el espacio temporal de tres meses quisimos conocer cuáles eran los diez temas más relevantes, y ese dato emergió de las mismas noticias que forman el corpus a través del procesamiento del lenguaje natural”, explica Pablo Balenzuela, investigador del Instituto de Física de Buenos Aires (IFIBA).
Los físicos representaron cada noticia como un gran vector en el espacio de palabras. La dimensión de los vectores viene dada por la cantidad total de palabras que posee el conjunto de noticias luego de ser depurada de términos no representativos del sentido como preposiciones y conjunciones; y cada componente da una idea de la importancia de dicha palabra en el texto. Luego utilizaron la técnica de Non-negative matrix factorization (NMF), para detectar aquellos artículos periodísticos que resultan más similares entre sí y que se encuentran agrupados en ese espacio a lo largo de una determinada dirección. La orientación en el espacio de palabras viene dada por una combinación de keywords que arrojó el procesado computacional y se puede representar mediante nubes de palabras que permiten visualizar el eje temático.
La “jerarquía” de un eje temático fue determinada por la cantidad de palabras que posee la noticia, es decir que la extensión es índice de relevancia entre notas. A través de un gráfico los investigadores muestran el peso dado a cada tema. Conjuntos de noticias que se parecen más entre sí y, a la vez, guardan distancia entre ellos.

“Si una palabra es un eje y cada documento está representado por un espacio que tiene 440 mil ejes, entonces cada punto en ese espacio de términos es una nota, y la proyección de esa nota sobre cada eje da una idea de cuántas veces fue usada determinada palabra. La técnica de matrices que usamos nos permite identificar cómo se agrupan los documentos a lo largo de los ejes temáticos. Luego, la proyección de cada nota sobre cada eje temático nos permite saber qué grado de pertenencia tiene la nota con el tópico”.
Ante una agenda repleta de información que se actualiza continuamente, como sucede con los discursos periodísticos, los investigadores se preguntaron cuál sería el número óptimo de tópicos para obtener una buena representación: “no hay una muestra recomendable de antemano, más bien preferimos definir el grado de resolución con que queremos observar cada tema. Aunque la elección puede ser arbitraria en el sentido de que cada tópico podría ser desgranado en varios otros; y también, pueden reunirse varias nubes en un macrotema”. En el trabajo, los autores realizaron esta operación con el gran conjunto “elecciones” y “persona desaparecida”, en relación a la desaparición y búsqueda de Santiago Maldonado.
“No conocemos la dinámica de la agenda en un diario sino su emergente. Es decir, vemos cómo es la evolución temporal de un tema en el medio seleccionado pero no sabemos por qué está definida de esa manera, si en la cobertura, por ejemplo, hay sesgo ideológico respecto a los temas, o cualquier otra causa. Observamos la dinámica, no la explicamos”, enfatiza Sebastián Pinto, estudiante de doctorado y coautor del paper.
Qué se escribe, qué interesa leer
Pinto cuenta que una vez identificados los diez tópicos y las palabras que los definen realizaron la búsqueda de los cinco primeros términos en Google Trends y, complementariamente, cuántas veces habían sido consultados por los usuarios en comparación con otros cinco términos asociados a otro tema. “De esa manera obtuvimos el peso relativo de los temas en las búsquedas cada tres días, con una muestra de aproximadamente dos mil tweets se realizaron indagaciones comparativas de palabras, básicamente, queríamos conocer cuánto se había hablado del tema en la red social”.
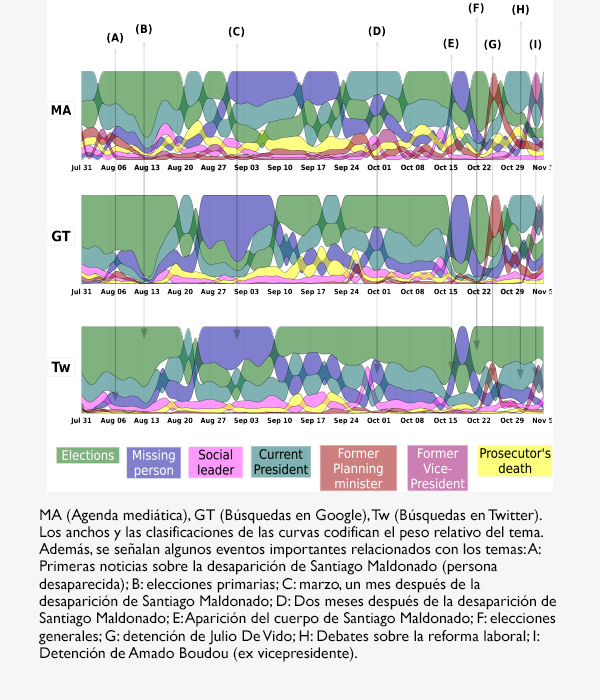
Por la forma en que los investigadores han construído el análisis, la Agenda Pública es definida por los temas que se encuentran en la Agenda de Medios y, por lo tanto, no sería posible encontrar temas de interés público que no se hayan publicado en los medios de comunicación en el período analizado utilizando la misma metodología. Sin embargo, “la misma limitación intrínseca proporcionada por esta metodología nos permite definir ambas agendas en el mismo espacio temático y, por lo tanto, realizar las medidas de comparación adecuadas”.
“La divergencia que usamos para medir es una medida de distancia entre las agendas. Si las agendas son parecidas la distancia es cero, por el contrario cuando las agendas son muy diversas la distancia se agranda. Si se compara la distancia dia a dia, en un momento la agenda pública y la agenda mediática se separan. Esta distancia se mide globalmente a la selección de temas. La distancia será cero cuando el público y los medios le den la misma importancia a un mismo grupo de temas”, dice Balenzuela.
El llamado efecto de realimentación, es decir la influencia de la dinámica de las redes sociales - la cantidad de clicks o el tiempo de lectura sobre la definición de la agenda- requiere de otro tipo de análisis que los investigadores planean estudiar más adelante sumando a los datos obtenidos modelos matemáticos.
“Quantifying time-dependent Media Agenda and public opinion by topic modeling” Sebastián Pinto, Federico Albanese, Claudio O. Dorso, Pablo Balenzuela
")
 (ES)")